How To Make A Multi Node Kafka Cluster
Introduction
Apache Kafka (from now on just Kafka) is one of the most frequently used message buses nowadays, and the reason is because has some key features that makes it the perfect tool in some scenarios (preserve consumption order per partition and allows parallel consumption = scales very well). Usually, is used as a Messaging System (for microservices architectures, decoupling applications, etc), but could even be used as a Storage System or for Stream Processing.
In this tutorial I will show you how to create a multi-node Kafka cluster with three different machines. Although, this tutorial is for administrators I think that is worth read for those that use Kafka in his daily development.
Recently, for one of my side projects I had the need of create a totally different database from another one. Insertions should occur in the order appears in database A, so when there is an insertion in database A must be another in the same order in database B, but the data coming from A should be enriched before inserted in B. To do it, I choose Kafka because gives me what I need and to have fault tolerance a created a cluster. The cluster has the following anatomy:
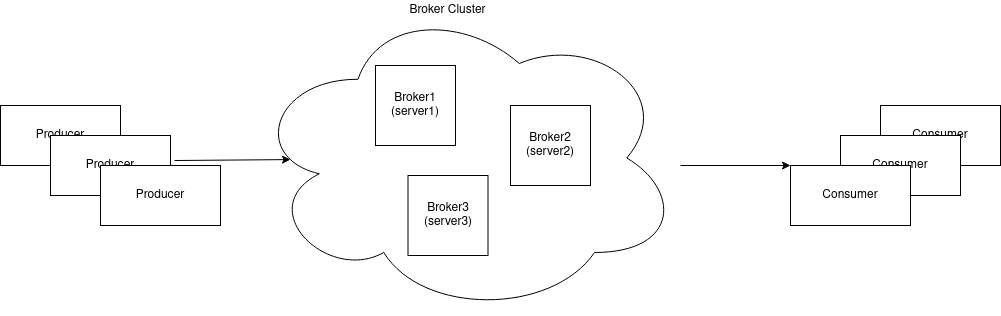
As usual, one of the server is going to act as the “leader” and the others as the “followers”. If the leader stop running one of the followers will automatically become the new leader. We have to carefully configure each broker with the correct parameters in order to fill our needs in the way we want.
For the time I’m writing this the last version of Kafka is 2.5.0 and is the one I’m going to use here (kafka_2.13-2.5.0.tgz). I assume that you have already installed java in your machines. I used Ubuntu 18.04 for this tutorial.
Make a ZooKeeper cluster
Kafka use ZooKeeper to persist its metadata: location of partitions and configuration of the topics (eventually this dependency
will be removed, Confluent post talking about it). So first, we need
to create a ZooKeeper cluster (ensemble how is called by ZooKeeper). There is no need to download ZooKeeper because it’s bundled with Kafka.
TIP: I always initialize a git repository within the folder where config files lives in the tools that I use. I encourage you
to do it inside the Kafka config folder (located in the root folder), this gives you two advantages (among others):
- Centralized config.
- Changes tracking.
Now, edit zookeeper.properties file inside config folder with the following:
tickTime=2000
dataDir=/path/you/want # be sure you have write permissions
clientPort=2181
initLimit=5
syncLimit=2
server.1=<IP1>:2888:3888 # every machine that is part of
server.2=<IP2>:2888:3888 # the ZooKeeper cluster should
server.3=<IP3>:2888:3888 # know about each other.The explanation of each option is (extracted from docs):
tickTime: the length of a single tick, which is the basic time unit used by ZooKeeper, as measured in milliseconds. It is used to regulate heartbeats, and timeouts. For example, the minimum session timeout will be two ticks.
dataDir: the location where ZooKeeper will store the in-memory database snapshots and, unless specified otherwise, the transaction log of updates to the database.
clientPort: the port to listen for client connections; that is, the port that clients attempt to connect to.
initLimit: (No Java system property) Amount of time, in ticks (see tickTime), to allow followers to connect and sync to a leader. Increased this value as needed, if the amount of data managed by ZooKeeper is large.
syncLimit: (No Java system property) Amount of time, in ticks (see tickTime), to allow followers to sync with ZooKeeper. If followers fall too far behind a leader, they will be dropped.
server.x=[hostname]:nnnnn[:nnnnn], etc: (No Java system property) servers making up the ZooKeeper ensemble. When the server starts up, it determines which server it is by looking for the file myid in the data directory. That file contains the server number, in ASCII, and it should match x in server.x in the left hand side of this setting. The list of servers that make up ZooKeeper servers that is used by the clients must match the list of ZooKeeper servers that each ZooKeeper server has. There are two port numbers nnnnn. The first followers use to connect to the leader, and the second is for leader election. If you want to test multiple servers on a single machine, then different ports can be used for each server.
Also, you need to create a file called myid inside the dataDir you specified with just the number of the server, for
my case I will have three myid files one in each server with just “1”, “2” and “3”.
Then, make a copy from zookeeper.properties for each machine:
cp zookeeper.properties zookeeper2.properties
cp zookeeper.properties zookeeper3.properties…and change the dataDir for each one, now you could launch each ZooKeeper server in each machine as follows (inside Kafka folder):
bin/zookeeper-server-start.sh config/zookeeper.properties & # in machine 1
bin/zookeeper-server-start.sh config/zookeeper2.properties & # in machine 2
bin/zookeeper-server-start.sh config/zookeeper3.properties & # in machine 3If you execute jps -l you should see something like the following:
4327 org.apache.zookeeper.server.quorum.QuorumPeerMain
4825 jdk.jcmd/sun.tools.jps.Jps…which means that you have running your ZooKeeper server.
The Kafka cluster
For the Kafka cluster we need to follow more or less the same steps than before, first edit server.properties file:
# ZooKeeper
zookeeper.connect=<IP1>:2181,<IP2>:2181,<IP3>:2181
# Log configuration
num.partitions=1
default.replication.factor=3
log.dirs=/path/you/want # be sure you have write permissions
# Other configurations
broker.id=0 # 1 and 2 for the others
min.insync.replicas=2Every config option means:
zookeeper.connect: comma separated list of ZooKeeper servers.
num.partitions: the default number of log partitions per topic. You could leave with 1 or change to the number you want. Bear in mind that the number of partitions could be increased if you want to process messages in parallel (a consumer could process messages from one or more partitions of a topic).
default.replication.factor: default replication factors for automatically created topics. Replication factor defines the number of copies of a topic in a Kafka cluster, in our case we have 3 machines, so we should put 3 here.
broker.id: An integer representing the id of the broker. Start with 0 and increment by 1 for each new broker.
min.insync.replicas: When a producer sets acks to “all” (or “-1”), min.insync.replicas specifies the minimum number of replicas that must acknowledge a write for the write to be considered successful. If this minimum cannot be met, then the producer will raise an exception (either NotEnoughReplicas or NotEnoughReplicasAfterAppend). When used together, min.insync.replicas and acks allow you to enforce greater durability guarantees. A typical scenario would be to create a topic with a replication factor of 3, set min.insync.replicas to 2, and produce with acks of “all”. This will ensure that the producer raises an exception if a majority of replicas do not receive a write.
With this config you are ready to go, just copy and paste the config file in each machine and change the broker.id. Then, execute the
following command in each machine:
bin/kafka-server-start.sh config/server.properties # machine 1
bin/kafka-server-start.sh config/server2.properties # machine 2
bin/kafka-server-start.sh config/server3.properties # machine 3ZooKeeper will know that a Kafka cluster is created, you could ask to ZooKeeper if the cluster is running with the following command:
zookeeper-shell.sh <IP1>:2181 ls /brokers/ids…and you should see something like this:
Connecting to <IP1>:2181
WATCHER::
WatchedEvent state:SyncConnected type:None path:null
[0, 1, 2]As you can see there are three brokers listed [0, 1, 2] now you can start using your cluster, but if you think about it
everyone could use your cluster that is not cool. For production environments you must secure the cluster.
Enabling SSL with Let’s Encrypt
I use Let’s Encrypt to enable SSL in my servers, for each machine I have a domain name and certificates for them, I will use these certificates to enable SSL in the Kafka cluster.
First, you have to create a keystore for each Kafka server, you have to generate a pkcs12 file from your .pem files. Usually,
your pem files are located in /etc/letsencrypt/live/[YOUR_DOMAIN], let’s move to this folder and execute the following:
openssl pkcs12 -export -in fullchain.pem -inkey privkey.pem -out keystore.p12 -name kafka1 -CAfile chain.pem -caname root…then import the pkcs12 file into a keystore (change example.com with your domain name and ‘STRONG_PASS’ for the one that you provide in the previous step):
keytool -importkeystore -deststorepass 'STRONG_PASS' -destkeypass 'STRONG_PASS' -destkeystore keystore.jks -deststoretype JKS -srckeystore keystore.p12 -srcstoretype PKCS12 -srcstorepass 'STRONG_PASS' -alias kafka1 -ext SAN=DNS:example.comTo check that everything is inside the keystore, execute:
keytool -list -v -keystore keystore.jks…also add the certificate to the JDK truststore:
keytool -trustcacerts -keystore $JAVA_HOME/lib/security/cacerts -storepass changeit -noprompt -importcert -file /etc/letsencrypt/live/YOURDOMAIN/chain.pemALTERNATIVE: you could, instead of add the certificate to the trust store of the jdk, create a truststore, this as simple as create
it with the chain.pem file:
keytool -keystore truststore.jks -alias kafka1 -import -file chain.pem…you will be prompted with a password for the truststore, also you have to put yes when ask if you want to trust it.
ALTERNATIVE2: another way to generate the truststore is by generating the truststore from your domain name:
openssl s_client -connect example.com:443 -showcerts </dev/null 2>/dev/null | openssl x509 -outform DER > example.der
openssl x509 -inform der -in example.der -out example.pem
keytool -import -alias example -keystore truststore.jks -file example.pem -storepass 'STRONG_PASS' -nopromptNow you have the keystore and truststore generated from your pem files. Remember that each three months you have to do the same thing to update your certificates, also remember to do these steps in every machine (the best way to not forget that is automating these steps in each machine).
The final step you have to do is to add the paths of our keystore and truststore to the broker config server, open your server.properties
(do it for every broker) and add the following:
listeners=SSL://example.com:9092
ssl.keystore.location=/path/to/keystore.jks
ssl.keystore.password=STRONG_PASS
ssl.key.password=STRONG_PASS
ssl.truststore.location=/path/to/truststore.jks # in case you add the certificate to the jdk put '/path/to/jdk/lib/security/cacerts'
ssl.truststore.password=STRONG_PASS # if you use cacerts put 'changeit' (default password of cacerts)
ssl.secure.random.implementation=SHA1PRNG
security.inter.broker.protocol=SSL
advertised.listeners=SSL://example.com:9092Changes are also needed for our client configurations (producers and consumers):
...
security.protocol=SSL
ssl.truststore.location=/path/to/truststore.jks
ssl.truststore.password=STRONG_PASS
...With all of this you have at least secured your cluster against man-in-the-middle attacks, you could continue adding SSL Authentication (two ways authentication), SASL Authentication and Authorization through ACL.
Conclusion
Creating a Kafka cluster is easy, maintain, administrate and securing it by your own could be a pain in the neck, as you can see in this post I only created a simple cluster of Kafka and added SSL to it, but I warn you that you will have to work towards the best configuration that fill your needs and this is something that could not be done in one single day.